Mutation analysis is a popular technique to assess the effectiveness of test suites with respect to their fault-finding abilities. It relies on the mutation score, which indicates how many mutants are revealed by a test suite. Yet, there are mutants whose behaviour is equivalent to the original system, wasting analysis resources and preventing the satisfaction of the full (100%) mutation score. For finite behavioural models, the Equivalent Mutant Problem (EMP) can be addressed through language equivalence of non-deterministic finite automata, which is a well-studied, yet computationally expensive, problem in automata theory. In this paper, we report on our assessment of a state-of-the-art exact language equivalence tool to handle the EMP against 12 models of size up to 15,000 states on 4710 mutants. We introduce random and mutation-biased simulation heuristics as baselines for comparison.
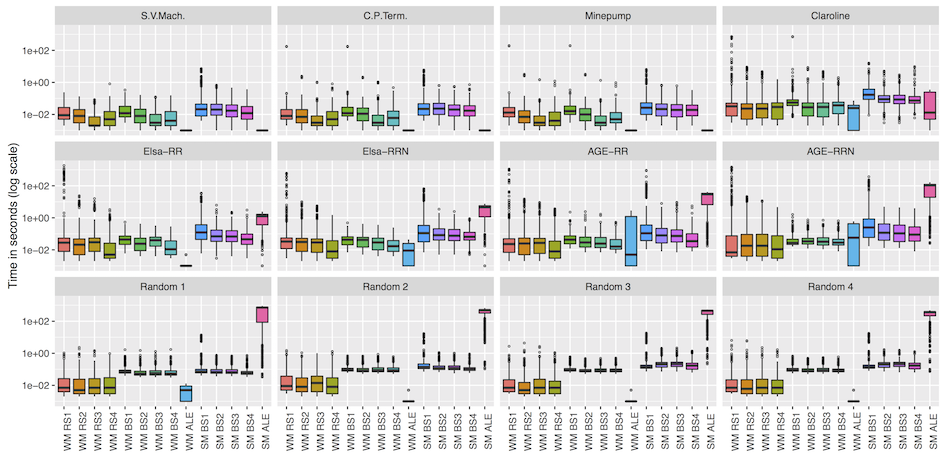
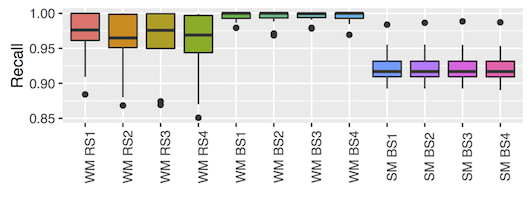
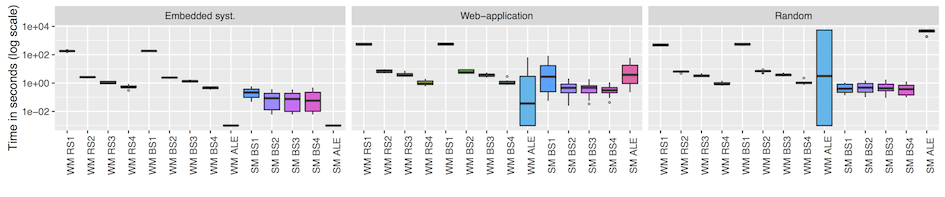
Our empirical assessment show that the exact approach is often more than ten times faster in the weak mutation scenario. For strong mutation, our biased simulations are faster for models larger than 300 states. They can be up to 1,000 times faster while limiting the error of misclassifying non-equivalent mutants as equivalent to 8% on average. We therefore conclude that the approaches can be combined for improved efficiency.
The mutation operators used for the assessment are described in the following document: mutation.pdf.
The evaluation has been performed using VIBeS v1.1.5: jar files are available in the Maven central repository (http://search.maven.org/). The input models, the mutation configuration files, and the scripts used to lauch the assessment and process the results are downloadable here: mutants-equiv-eval.zip.
The tools used are in tools/, they have been used with the following utilities:
Before running the evaluation, one will need to compile hknt-1.0 (a copy of the sources is available in tools/hknt-1.0.tar.bz2) using OCamlbuild and copy or link the 'hkc' utility to tools/hkc.
Input models and configurations used to generate the mutants are in models/:
Mutants are generated in mutants/ and results of the executions are stored in results/. Tables and graphics (resp.) generated from those results are stored in (resp.) tables/ and graphics/.
The Makefile contains in this directory will launch the different steps of the evaluation and the process of the results.
We run the Monte-Carlo (MR) and local random (LR) algorithms with 4 different values of delta and epsilon determining the number of traces selected and executed (N):
To run the language equivalence algorithm (ALE), we use HKC. This tool allows to check automata language equivalence check on non-deterministic TSs using different strategies: the automata may be processed either forward (fwd) of backwards (bwd), and the exploration strategy may be breadth-first (bfs) or depth-first (dfs). For each mutant, we execute the HKC library using each of the 4 possible configurations.
Summary tables are available here : tables.pdf.
The complete results of the different executions are available here: results.rds.zip.